
Notes on "The Illusion of Thinking"
The Apple Machine Learning Research team released a paper in June 2025 that questions whether LRMs actually think and if such models can reason when the complexity increases.

With the huge advancements on Generative Artificial Intelligence, the Software Industry is changing at unprecedented pace. Large Reasoning Models (LRMs) are helping software professionals write, debug and deploy code faster than ever. Software is, and will continue to be, eating the world, now powered by Artificial Intelligence.
I started doing academic research on these topics and came across what is likely the most popular paper of the summer of 2025, published by Apple: The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity by Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio and Mehrdad Farajtabar.
What are the paper highlights?
Apple Machine Learning Research team identified the mathematical and coding benchmarks made for LRMs may suffer from data contamination and might not provide useful insights regarding the reasoning itself.
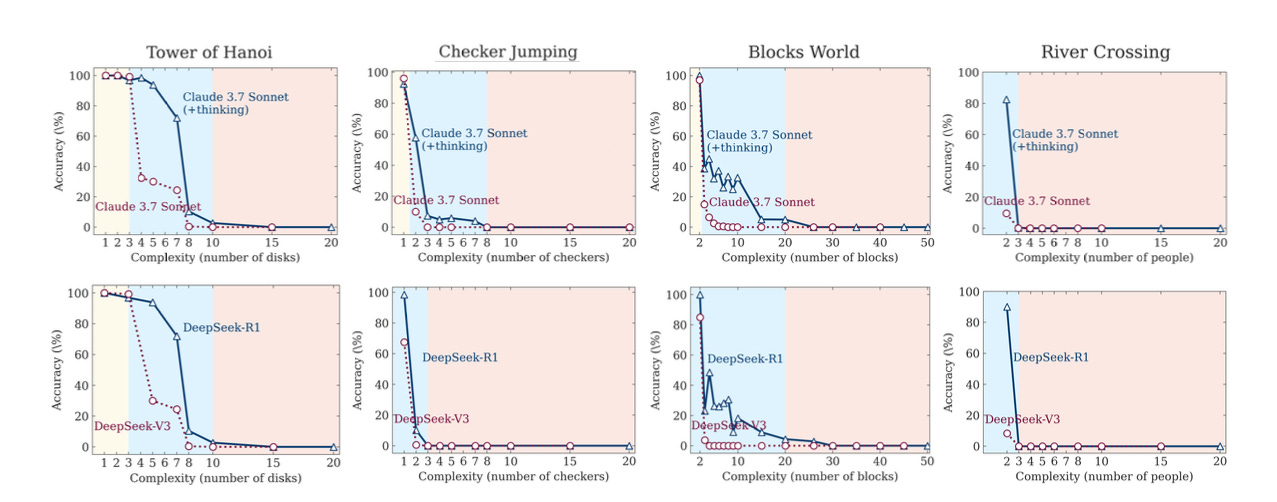
To tackle this issue they decided to create a testing environment using controllable well-known puzzles such as Tower of Hanoi, Checker Jumping, Blocks World and River Crossing.
They were able to control the experiment by increasing its complexity (the variable depends on which puzzle was being used). This experiment allowed them to understand how LRMs think and how accurate they are.
I believe the most important conclusion of their experiment is that LRM reasoning drops abruptly when the complexity of their task increases. For instance, in the previous diagram, regardless the model used, when the number of disks increases in the Tower of Hanoi puzzle, the accuracy drops slowly, but after five disks it starts dropping immediately.
Are puzzles a good example?
It depends. I understand the reason behind using puzzles. Puzzles such as River Crossing or Tower of Hanoi have known rules and defined parameters which can be scaled. Could the paper’s experiment be improved or done slightly differently?
It probably could, but in my humble opinion, this paper leaves a big question: should the software industry rely on LRM powered tools to develop, maintain, fix, deploy, test production code?