
Notes on "Evaluating Large Language Models Trained on Code"
Codex is the model behind Github Copilot. My notes are not focused on Codex but on HumanEval, a functional correctness dataset designed as the primary benchmark of Codex model.

The research that led to codex builds upon a previous investigation of GPT-3 which demonstrated an unexpected ability to generate simple programs from Python docstrings. Following this success, the research team developed a specialized GPT model, Codex, for code generation tasks. Codex is the core technology of Github Codepilot.
Chen M. et al. - Evaluating Large Language Models Trained on Code - https://arxiv.org/abs/2107.03374
Docstrings (documentation strings) are used in Python code to define behavior of a function or a class. Chen M. et al. used these docstrings as the prompt for the model. For example, the following code snippet describes a docstring.
def sum(a, b):
""" returns the sum of a and b """
return a + bHumanEval
As aforementioned, my goal is not to focus on the Codex model itself but in the dataset they used to test it. HumanEval is a dataset created to measure functional correctness.
The primary motivation for creating HumanEval was a major deficiency in existing benchmarks: they relied on match-based metrics.
The problem with match-based metrics
What is match-based metric? Measure text similarity by comparing generated text to a single reference solution. They quantify the overlap sequences of words (n-grams).
What is the problem with match-base metrics? Exists multiple different ways to implement a valid code solution to a problem. A simple task of summing two numbers can have countless correct implementations. In this case, if the generated code differs from the single reference solution, it is considered as incorrect (getting a low-score).
Match-base metrics are not fit to assess code generation because it does not evaluate functional correctness. This is the main reason behind HumanEval.
The HumanEval dataset
HumanEval contains 164 original programming problems in Python assessing language comprehension, algorithms and simple mathematics. These problems cannot be found in public training data which drastically reduces the chance of data contamination. The dataset forces the model to reason and generate a better solution, instead of trying to generate a solution from similar code on its training data.
In short, HumanEval evaluates functional correctness by providing a curated dataset and testing the generated solutions against unit tests. It uses pass@k as the main evaluation metric.
Pass@k metric
HumanEval uses pass@k as the main evaluation metric which represents an estimated probability that a model will generate a correct solution in the first k samples.
pass@1: the probability of the first generated solution is correct;
pass@100: the probability of having one correct solution in one hundred samples;
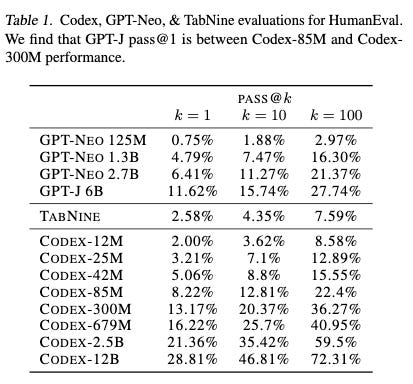
The original paper showcased the performance of GPT-NEO, GPT-J and Codex with different tokens sizes using HumanEval benchmark. It is important to highlight the Codex-12B results. It achieved a pass@1 score of 28,81% and pass@100 score of 72,31%. Within 100 generated outputs, Codex-12B had a 72% chance of producing one correct solution!